
By Eddy Davies – Data Science Associate
Introduction
As data scientists, we are always looking to combine disparate data sources. This creates a more complete view of the problem case at hand. Unfortunately, the data we desire is not always easily available as a dataset. However, there is often a website that has some useful information we can acquire and transforms into a dataset. This is where web scraping comes in. In the blog we look at using Python and Scrapy to do this.
Web scraping is the process of extracting data from a human-readable format automatically into a data structure. There are a few options available within Python for scraping data but the one I believe to be the simplest and most complete solution is Scrapy. All scraping solutions rely first and foremost on selectors.
Selectors
Selectors extract data from a HTML page section that contains the information. Be that text, images, or links to other pages to scrape. The inspect page view can be accessed with a right click on a given webpage from within a web browser, with a focus placed on the section that is right-clicked or highlighted (on a given webpage) and as shown in the screenshot below displays the HTML that is behind the webpage.
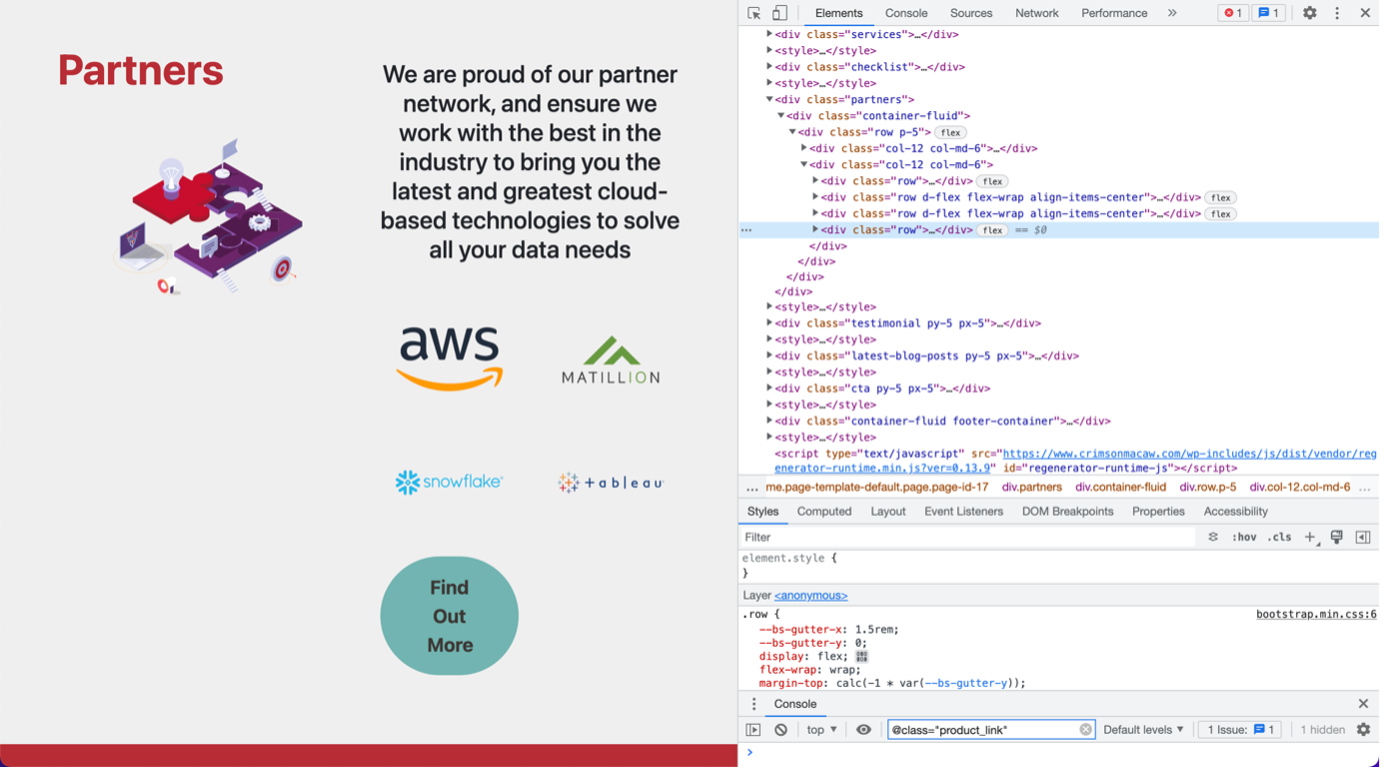

To select the required one of these HTML elements there are two types of selectors in Scrapy; XPath and CSS.
They both have their benefits; CSS is generally simpler, but XPath is better at dealing with nested data.
Extracts all <div> elements
div = response.xpath(‘//div')
Extracts all <p> inside the div
div.xpath('.//p')
After any selector .get() will pull just the first match to the search whereas getall() will pull a list of all the matches to the search.
Text or Attribute
Once you find the HTML element you need, you will either want to extract the text inside or a particular attribute. Often the ‘href’ will hold a linked page:
Select the text from an element:
response.xpath('//span/text()').get()
response.css('span::text').get()
Select an attribute:
response.css('base::attr(href)').get()
response.css('base').attrib['href’]
If you are extracting a link, you can attached the relative URL to get the full URL:
relative_url = response.css('.e1fl2ivl2').css(' a').attrib['href’]
'/public/blogs/ethical-ai-now-is-the-time-to-act'
url = response.urljoin(relative_url)
If you are looking to select all <div> elements occurring first under their respective parent’s use:
response.xpath('//div[1]')
However, if you instead need to select all <div> elements in a document, this will retrieve just the first one of them:
response.xpath('(//div)[1]')
Running Scrapy
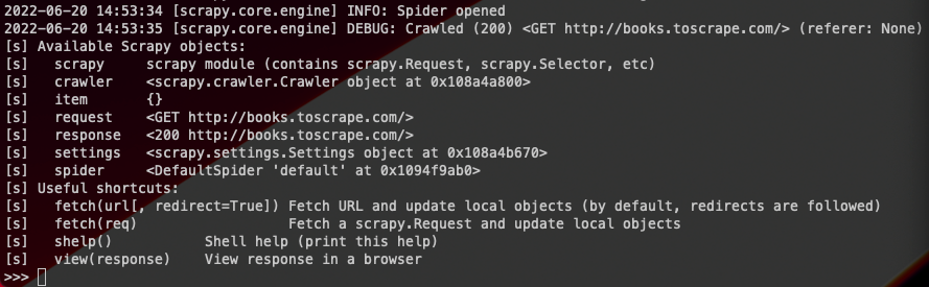
An exploratory scraping stage helps to find which combination of the above selectors will extract the desired elements for a given site. This is the main use for the web scraping Scrapy shell, which activates with this simple command in the terminal:
scrapy shell <url>
- use the selectors
- define variables from selections
- run FOR loops through lists returned by
.getall().
However, once you need to start running a full program, I would recommend using this snippet of code:
if __name__ == "__main__": process = CrawlerProcess() process.crawl(CollectExample) process.start()
In this code, you will need to reference the name of your spider class (i.e., CollectExample), which we will discuss the design of in the next section. There is an alternative method that requires you to run your spider from the terminal, but when working from PyCharm I found this method more convenient. If you are looking to use Scrapy in a Jupyter notebook check out this article.
Spider Class
A spider is the part of this scraping program that “crawls” through the website, extracting content and other links to scrape as it goes.
The class must be created as a subclass of Spider as seen here:
class CollectExamples(Spider):
name = 'Example Title'
custom_settings = {}
start_urls = ['https://www.example.com/']
def parse(self, response):
for h3 in response.xpath('//h3').getall():
yield {"title": h3}
These variables override the Spider super class variables; name is used to identify the spider among others you may be running, custom_settings will be described in more detail further down this blog and start_urls specify the URL or list of URLs to initially scrap from. To customise the initial URL selection start_request() can be overridden instead of or as well as. Then the parse function again overrides a superclass function and is the function which will be called first on each of the start_urls. The Python logging package can be used seamlessly with Scrapy to easily provide various levels of logging.
Yielding
Once a selector is in place there are two main options. If you have selected a link (usually from a ‘href’ attribute) from, for example, a page of results and you need to scrape each of these pages, this is the time to yield a ‘request this’ form:
yield Request(url, callback=self.parse_api, cb_kwargs=dict(title=title))
In the request function, the callback argument specifies the scraping function to run on this link, which should contain a similar use of selectors as the parse class. The cb_kwargs argument passes a dictionary where the key is the name of parameters in the callback function and the values will be passed to that function. The request will then add to a scheduler queue this link along with the attached details and they will be scrapped after the start_urls.
If alternatively, you have found a piece of data that you wish to store you can yield an item. This can be either DataClass, dict, attr.s or Scrapy item object. A dict, the simplest option, is a good place to start:
yield {"title": "Turtles All The Way Down", "rating": 5, "author": "John Green"}
However, one of the other options will be better in the long term to build a more robust and reliable program. This is because they allow the exact data structure and data type. Regardless of the choice, outputs pass to the item pipeline and save to a set file.
Settings
The settings can be set in an external file but I found it easiest to include them in the spider. There are a few key settings that I believe will be useful for almost all projects you will work on. There are a variety of other settings available for niche situations to use as well. First is the feeds key that specifies the output file path, the file type (CSV, JSON, JSONLines or XML) and whether to overwrite the existing file. Then there is an item pipeline this specifies a series of functions to pass each piece of data through, with the value for each specifying the order to run them in (for more information on the pipeline function structure see here).
With the two final settings, we can prevent any websites from blocking the scraping requests. Auto throttle slows down the requests, waiting between repeat requests. User-agent tells the website that this is just a browser accessing it.
custom_settings = {
'FEEDS': {
f'{DATA_PATH}/reviews.jsonl': {
'format': 'jsonlines',
'overwrite': True
}},
'ITEM_PIPELINES': {
'scrap_retail_reviews.lib.to_multi_files.ContainsReview': 200,
'scrap_retail_reviews.lib.to_multi_files.ExtractUsers': 300,
},
'AUTOTHROTTLE_ENABLED': True,
'USER_AGENT': 'Mozilla/5.0 (compatible; Googlebot/2.1;'
' +http://www.google.com/bot.html)'
}
Putting it all together
First, I switched to the folder for my GitHub repo, activated my Python environment and started the web scraping Scrapy shell, to allow me to test the selector code. Make sure to run pip install scrapy before this if you haven’t already got it installed on your Python environment. We will be using books.toscrape.com, an example site for exactly this type of demonstration or experimentation.
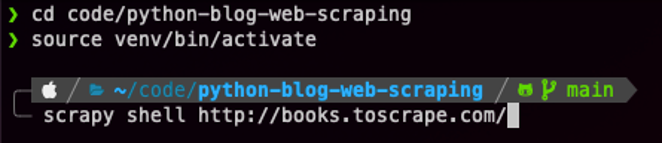
Inspect
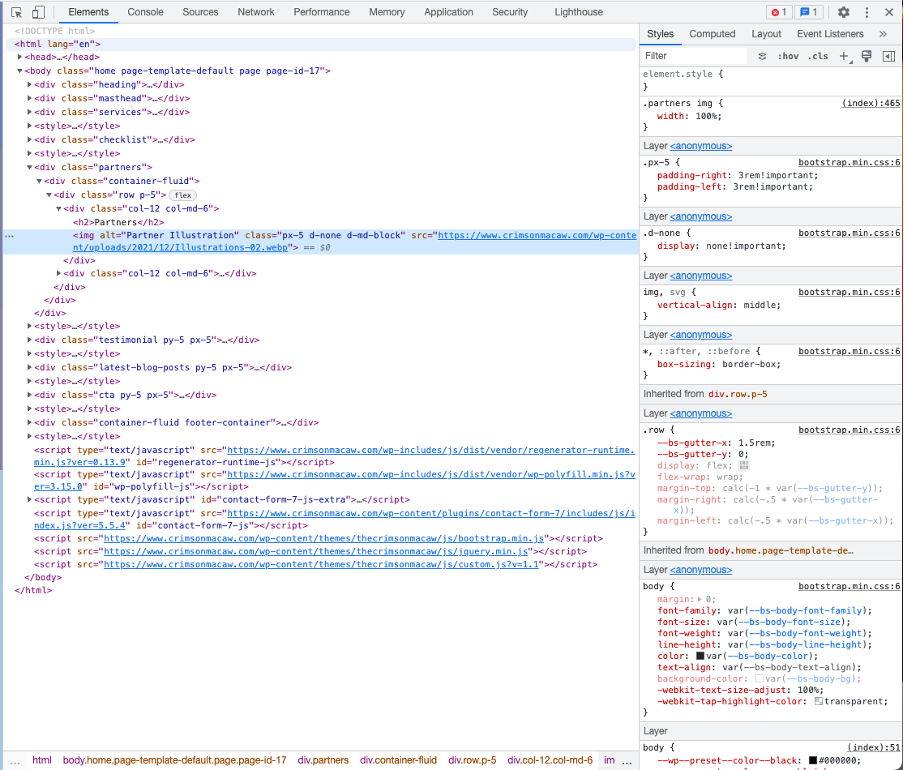
Now we have the web scraping Scrapy shell launched, switch back to your browser of choice and load up the website you are scraping. The first option to be aware of is the inspect menu, which allows us to see the code underlying on the webpage. By right-clicking on an entity, this will open with the target HTML element selected.
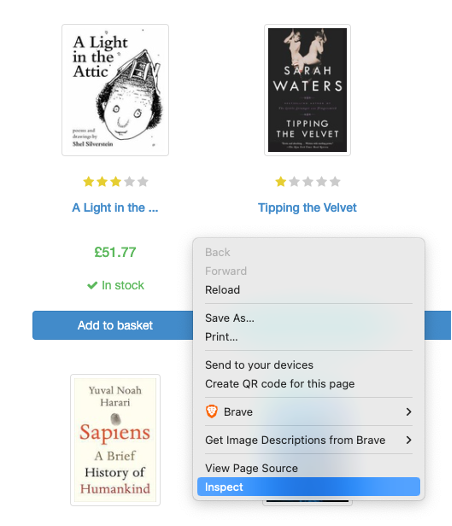
As you can see here this highlighted element is using an article element with a .product_pod class. For this example, it’s clear what element and class we are looking for.
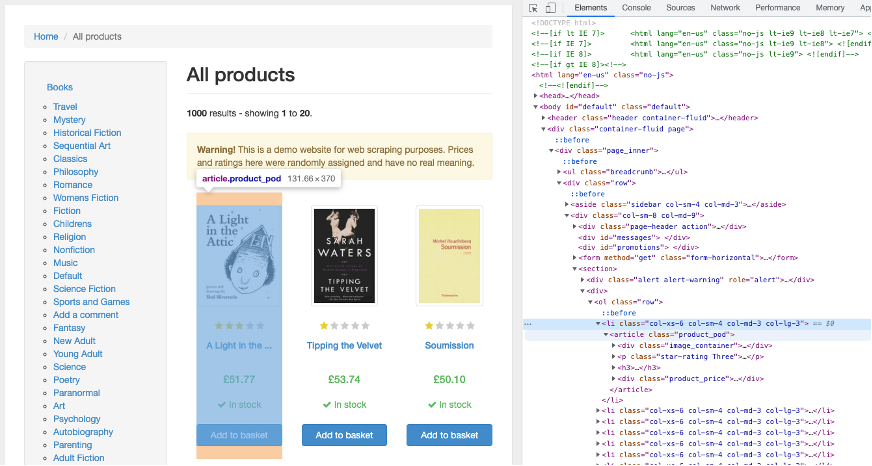
Selector Gadget
In more difficult situations I would recommend the use of the Selector Gadget extension. We can quickly get the same information from the inspect technique. We do this by moving the cursor until our element has an orange ring highlight.
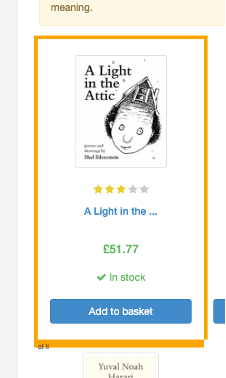
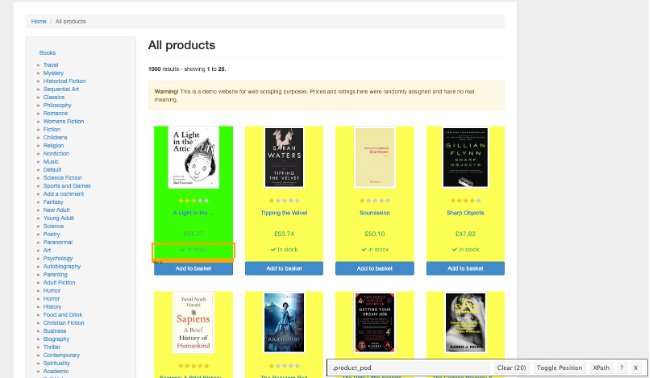
This tool is particularly useful when dealing with a complex selection, such as all the 4 or 5-star ratings. Clicking on a yellow element will add it to the current selection. We can remove exceptions we do not want by clicking any items highlighted in yellow.
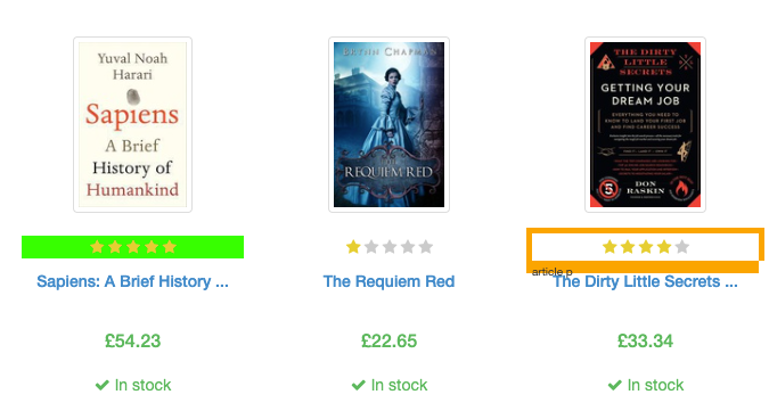
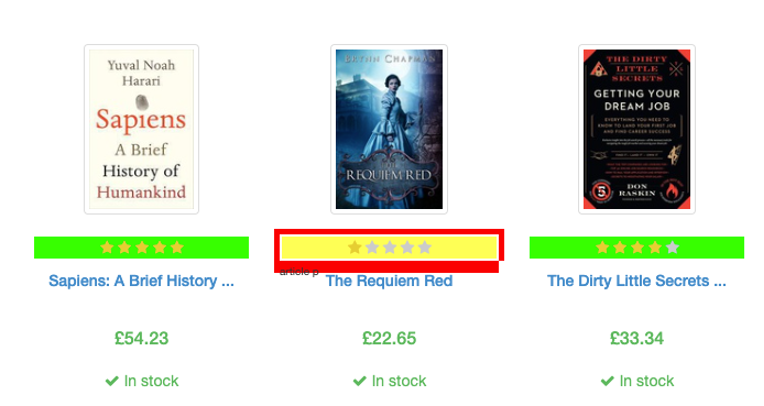
This allows us to view the selector shown below for our highly-rated books.
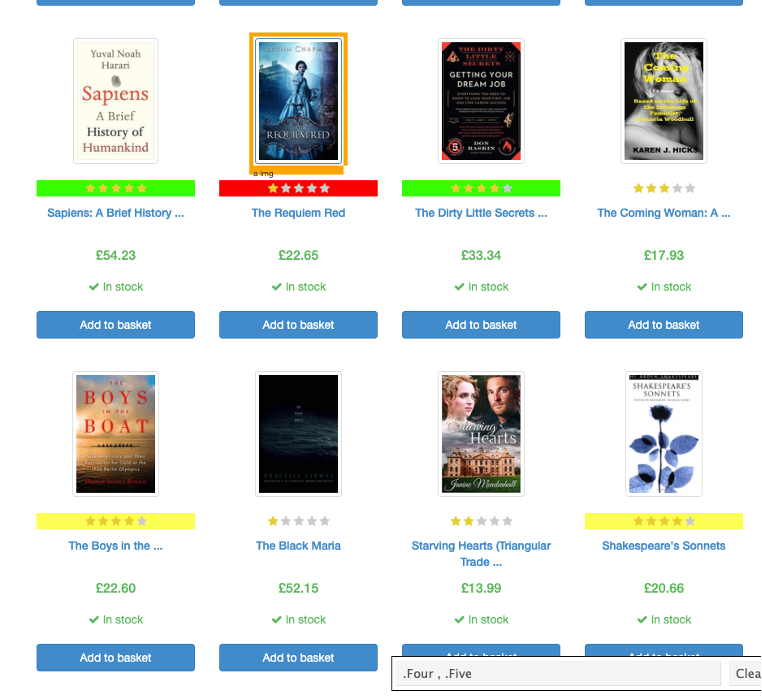
Back to Scrapy Shell
Using the CSS selectors that we identified in the last section, we can start to outline in the web scraping Scrapy shell the actual code we will need to run for our program. We use .css() with the .get() but adding that into a print statement renders the \n as new lines and we can clearly see the section of HTML we are working with.
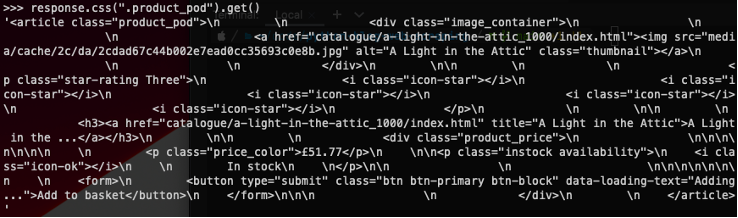
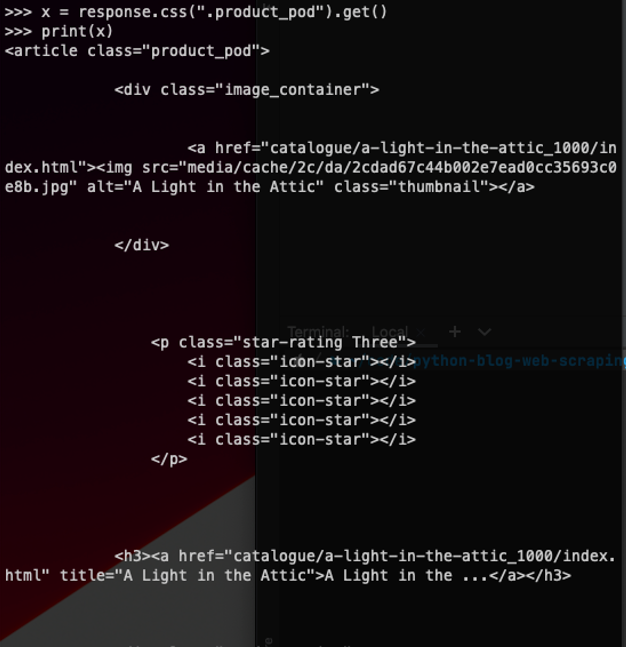
We can see that the URL we are trying to access is stored inside an <a> element, so we select that and then access the ‘href’ attribute to get the relative URL. This can be then converted to a complete URL using the .urljoin() function.


Compile into Project
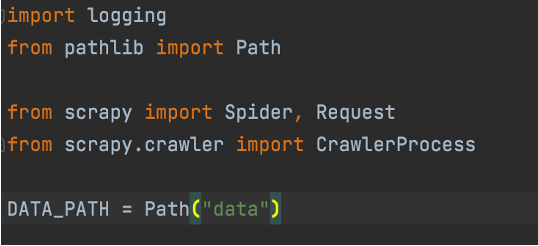
Bringing back together all the components mentioned in the early sections and the specific selectors we have chosen in the shell we can create the following Scrapy Python application. First, we import the required packages and functions, and then set the data location for the outputs.
Then we have the spider class, starting by overriding the key variables and selecting the custom_settings. Specifically, here we point to the second class which will process the initial data we scrape.
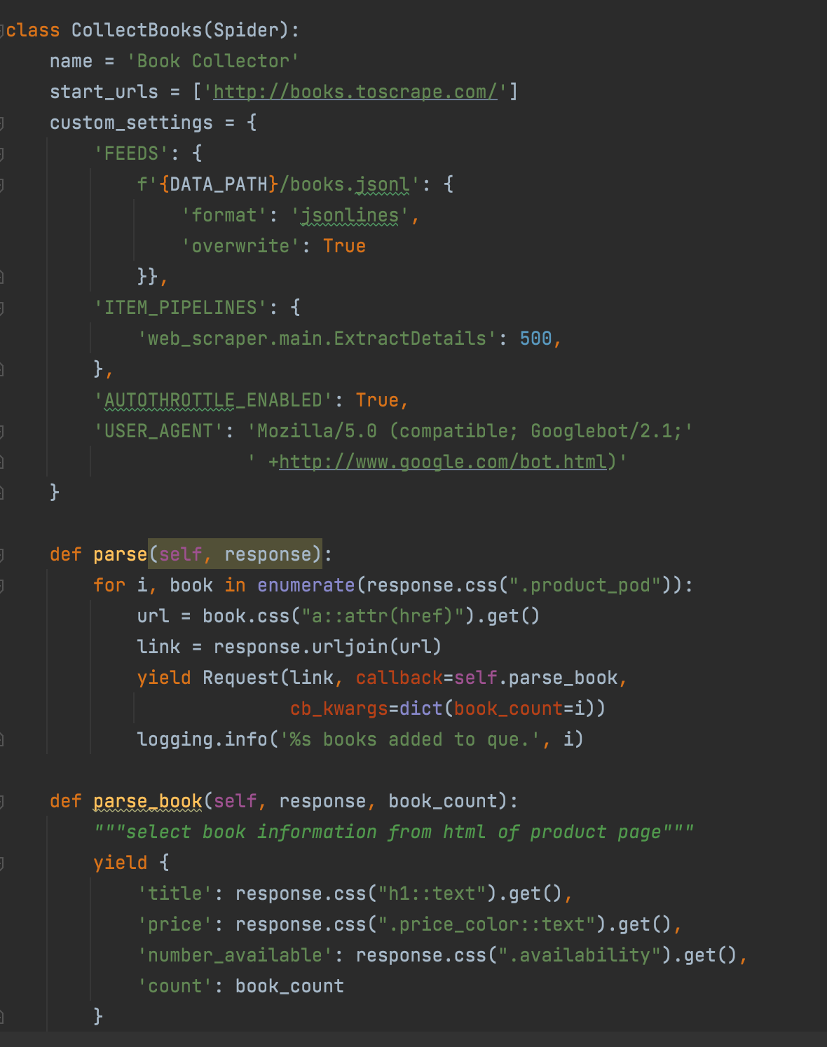
The parse function we know will be run first, then once a book is selected, we pass that link request to a function with the callback=self.parse_book and the book_count. This function extracts from each book page the particular details we are interested in and yields them as a dict. These will then be passed through the functions in ExtractDetails, an item pipeline always runs the process_item() function and passes the items in the item parameter.
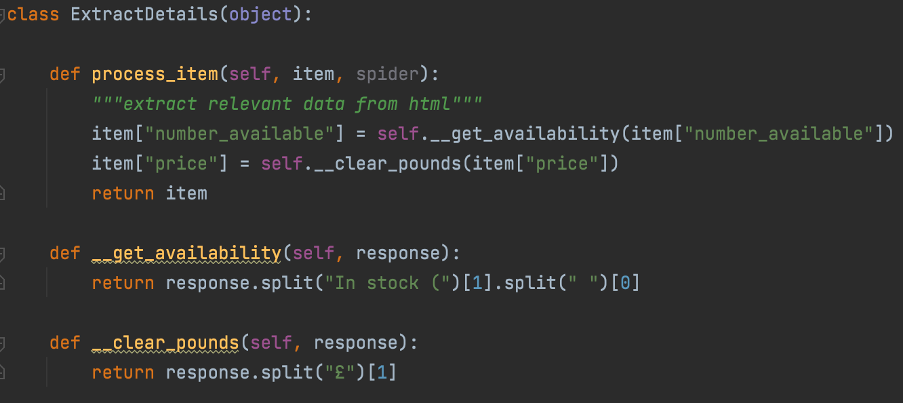
This class uses a few private functions to split up the components into nice, testable chunks (but that is for another blog). Below you can see the code we then used to run this spider from the main.

Conclusion
I have demonstrated a variety of ways to use selectors to extract the required HTML elements from a webpage using either XPath or CSS. We’ve also covered extracting text or attributes as required from them. We also learned how Scrapy spiders can crawl through a variety of pages and feed the content into an output.
Then, I ran through a worked example to show this running in practice. Hopefully, this has helped get you up to speed on the key things to know about web scraping.
Need help with a bigger project or want to know more? Please get in touch with us here.