
By Chris Knight – Senior BI Engineer
Here at Synvert TCM, we use dbt, a data transformation tool to help build Snowflake data warehouses for our clients. You can find more information about dbt here.
Following on from my previous dbt blog post, I wanted to discuss our approach to managing multiple environments in our dbt projects. At Synvert TCM, we tend to use separate Snowflake accounts to provide physical separation of our development, test and production environments. We do this with a single organisation account used for billing. This means that we need a different approach to working with multiple environments than that encouraged by the usual dbt setup, whereby users will have separate, environment-specific databases within a single account.
Some advantages of having separate accounts are;
- More security isolation. Since users need to be added to each account there’s no risk of misconfigured roles providing access to something a user shouldn’t have
- Easier to track credit consumption/expenditure for each environment
The Solution
The solution to this is to create a Snowflake account for each environment and use an environment variable in dbt to set the Snowflake account. In the example shown below, we have added an environment variable for the Snowflake account using Jinja2 syntax.
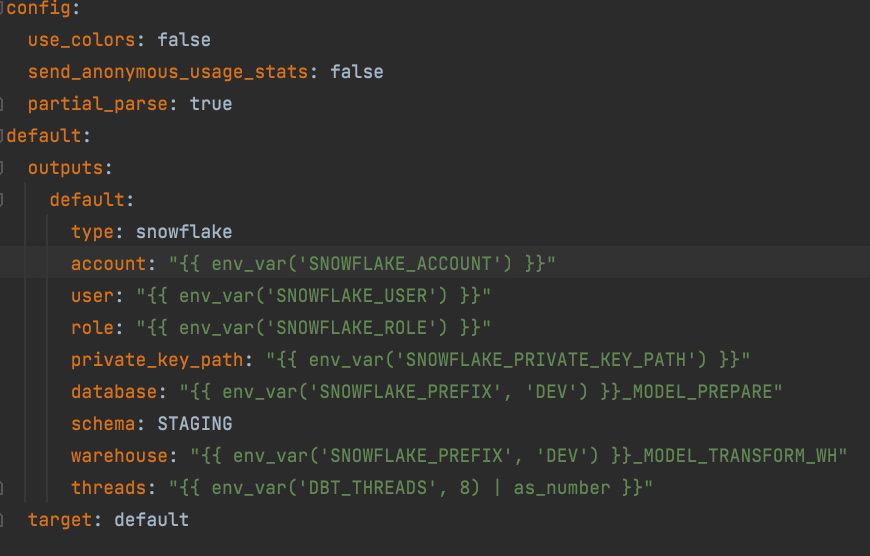
During the development phase of a project, when we need to run dbt locally, we manually assign the variable to our Snowflake dev account.
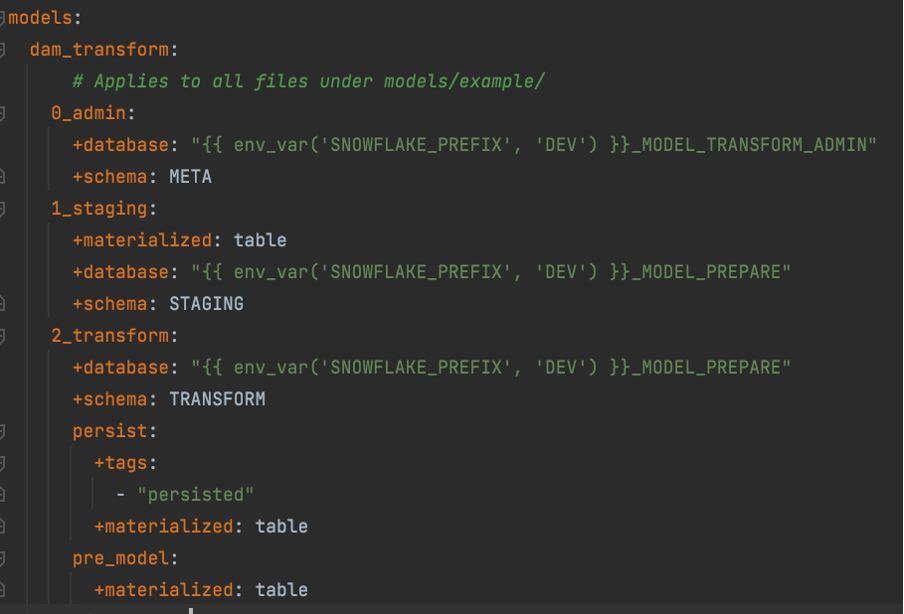
On most projects, we use a naming convention for naming Snowflake databases with an environment-specific prefix. This means that we need to use another variable to set this prefix dynamically.
This snippet of the dbt_project.yml file shows this in use:
Note that we have specified a default value wherever we use the variable. This is to avoid errors when building dbt inside a Docker container. This process includes running the ‘dbt deps’ command to install additional modules, which would give an error if any of the environment variables did not exist. Note that this behaviour was fixed in v1.0.2.
We have a variable for snowflake_prefix rather than variables for each database/environment is due to a limitation in the number of variables allowed when running dbt inside a Docker container on AWS.
At Synvert TCM, as part of our CI/CD pipeline, we use Github Actions workflows for packaging dbt into Docker images. The environment variables are used to build the dbt image for the correct environment. The image is then configured so that it can easily communicate with our Github organisation. This results in a much leaner dbt image.
Limitations
A limitation of this approach is that it’s not possible to take advantage of the partial_parse functionality within dbt. This is a feature whereby dbt will only parse the changed files, or files related to those changes when dbt is run. This can reduce the overall run time.
The reason for this is that each time the environment variable changes or a CLI variable is passed in, dbt will bypass partial parsing as it needs to rebuild the manifest for all objects.
To work around this, we build a Docker image of the dbt project for each environment, with the account variable set accordingly. This means that we can leverage partial parsing resulting in quicker dbt invocations.
Conclusion
If you plan to use dbt in a scenario where you have a separate Snowflake account for each environment, then it’s worth considering this approach. Its especially useful when using dbt within Docker containers.
Want to find out more? Get in touch here.
