
By Chris Austin – Senior BI Engineer
If you’ve ever found yourself wondering how to solve EDW query contention with Snowflake, we’ve got the answer for you. At synvert TCM (formerly Crimson Macaw) we use this feature a lot, so check out our guide on what we do below for using Snowflake to solve EDW queries.
What is Snowflake?
Snowflake is a market-leading cloud data warehousing solution which offers flexible storage & processing of data. One of the key advantages of the Snowflake architecture is its separation of compute and storage resources, giving it a critical edge over the traditional data warehouse. Now, we know more about the tool itself, let’s find out how we can go about using Snowflake to solve EDW queries.
Contention Issues in Traditional EDW platforms
In traditional architectures, all database queries compete over the same resources. A user running a report may find that the performance of the system is less good during the hours when an ETL is running. As a result, we should schedule some processes carefully during more idle periods for the database. For example, running the ETL overnight when the volume of user queries is low.
Global user bases and the need for 24/7 reporting have accentuated these resource constraints. With users operating in multiple time zones, it may be impossible to find a window of time to run the ETL without impacting reporting performance. The separation of storage and compute resources within the Snowflake architecture offers a comprehensive solution to this problem.
How does Snowflake work?
Snowflake operates a multi-cluster, shared data architecture whose service, compute and storage layers are physically separated but logically integrated. Individual workloads can be allocated to distinct compute resources that can scale independently of one another. This removes any chance of contention over resources.
The diagram below shows the basic Snowflake architecture.
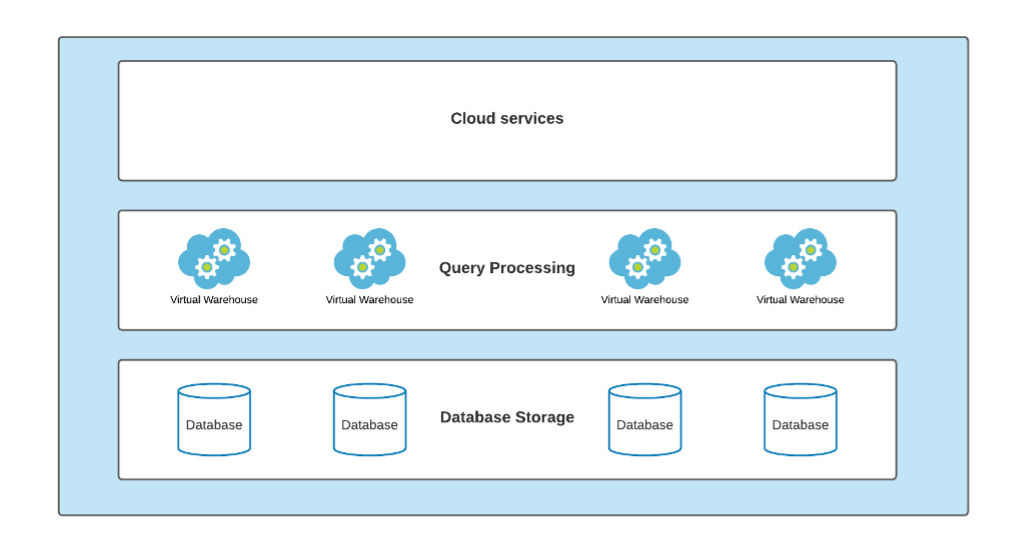
The Cloud Services layer handles key global processes such as authentication, access control, security, metadata management and query optimization.
The processing layer consists of multiple virtual warehouses, which are fed into clusters. These clusters are physically separate from both each other and the data located in the Database Storage layer. As such, the activity of one virtual warehouse has no impact on the performance of any others.
A virtual warehouse is a discrete allocation of compute that is used for reading and writing data from/into the shared Database storage layer. Except for caching purposes, data is not persisted inside the virtual warehouse.
Each virtual warehouse is provided with a full transactional history of the database(s) by the Cloud Services layer, such that queries will always read the latest consistent version of the data based on the most recent commit. We maintain consistency across all virtual warehouses without locks or contentions.
Why does this matter for contention?
Virtual warehouses can be configured specifically to handle different processes such as ETL and analytic queries. This means data loads and user activity can operate harmoniously.
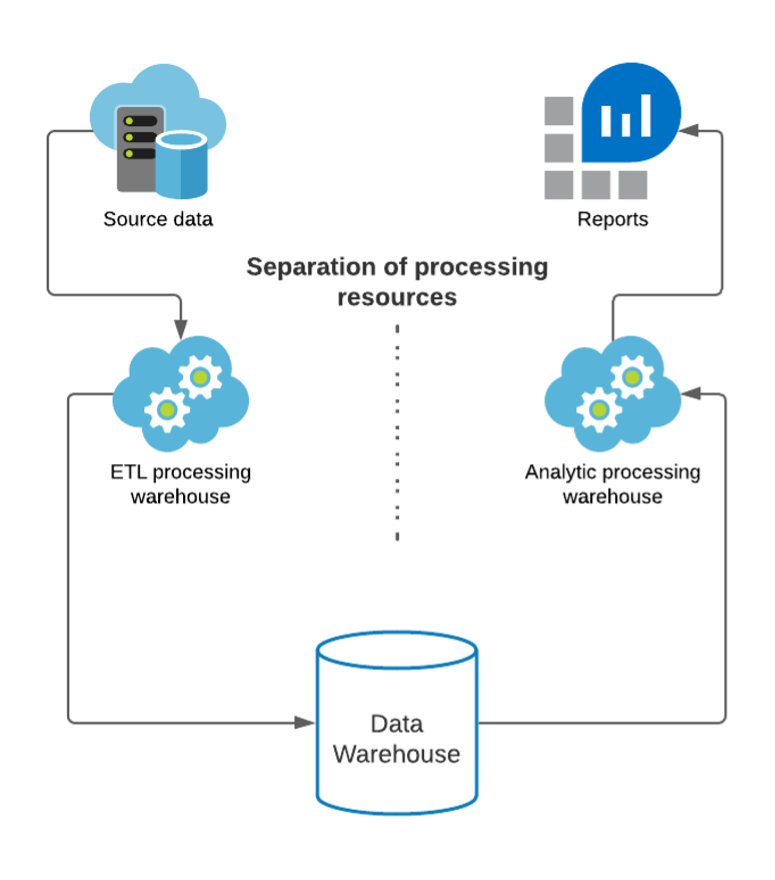
For the provisioning of ETL and analytic-specific virtual warehouses, consider the following:
- A high analytic query load would be serviceable by provisioning additional warehouses within a multi-cluster warehouse. This will offer a wider pool of compute resources to service the large volume of requests
- A smaller number of intensive queries from an ETL would be best when selecting a larger virtual warehouse size. It will offer more compute resources for a smaller volume of complex requests
In both cases, the AUTO_SUSPEND property can be configured to suspend the virtual warehouses when they are not being used. This helps preserve credits and avoid paying for processing resources when we don’t need them.
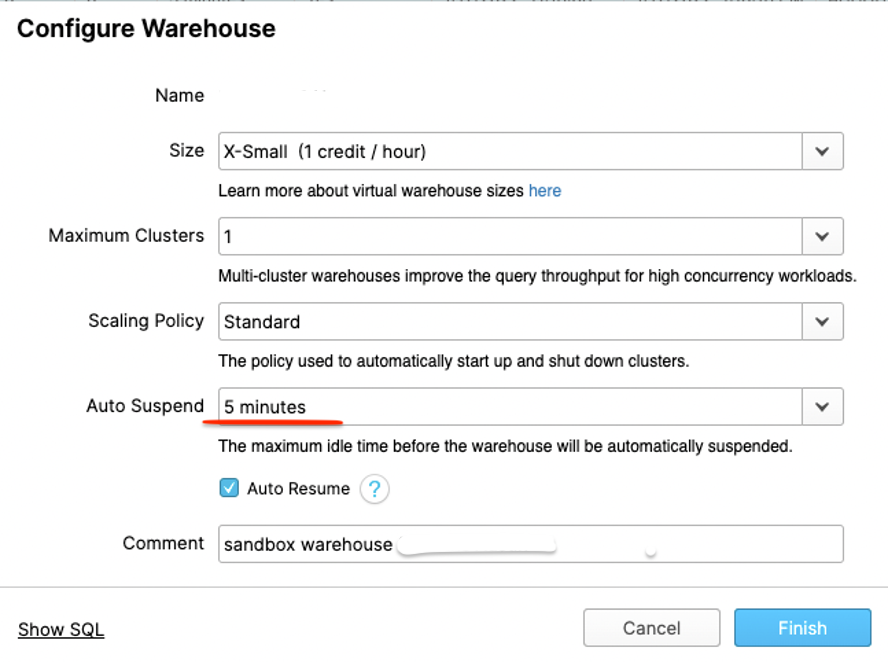
By separating the ELT and analytic resources, we can also avoid paying for the coverage of a larger virtual warehouse when the ETL is not running. Resources are only a requirement for users’ queries.
With multi-cluster warehouses, there is a minimum/maximum number of warehouses we can configure (via the MIN_CLUSTER_COUNT and MAX_CLUSTER_COUNT properties). This means a cluster will always revert to a single warehouse and only invoke additional resources when needed. It will not provide additional warehouses beyond a certain number – again useful for pricing.
We can take this further to support other scenarios
Imagine, within an organisation, a scenario where the analysts working in the Customer Service department run regular reports to support operational decision-making. Then comes the period end, the Risk or Finance department needs to run very intensive and complex queries. This leads to a degradation of performance for customer service analysts, reducing their ability to perform in their role effectively.
By provisioning separate compute resources we can solve this and tailor it to the needs of departments. For example, Finance could access a separate larger virtual warehouse at period end to run their complex queries in a timely fashion. The Customer Service department can use smaller auto-scaling virtual warehouses to support their continuous less complex queries daily.
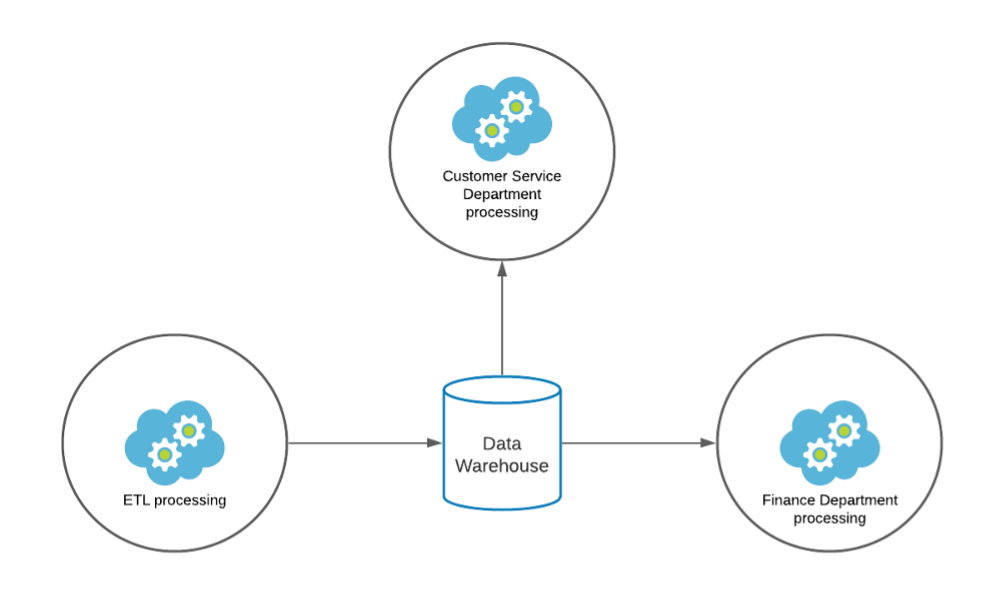
In this scenario, Snowflake allows very specific tailoring of resources for different use cases, allocating billing accordingly between different departments. In this example, between Finance and Customer Service. Any heavy queries run by Finance will not impact the ability of the Customer Services teams to access the data they need. When considering the cost of resources, users & business units need not be constrained by a central IT budget which usually results in a compromise for all parties. Instead, users can access resources purpose-built for their use case to maximise productivity and provide transparency on cost.
Conclusion for using Snowflake to solve EDW queries
The Snowflake architecture offers vastly increased flexibility in the provisioning of compute resources compared to traditional approaches. The separation of compute from storage is a key selling point of the solution. Undoubtedly, It allows the user to strike a sensible and flexible balance between resources and cost, whilst maintaining a great end-user analytic experience.
Want to find out more? Need support on your own data journey? Get in touch here.