
By Stephen McCririe – Senior BI Engineer
I hope you enjoyed Part One of our Matillion Orchestration blog series.
In the next part of this series, I am going to look at creating a template that can be reused and depending on which variables are passed in; truncate a table. This technique helps support the ability to choose between performing a full or incremental load.
Matillion Orchestration: Let’s start
The whole point of creating a template is to allow Matillion to perform a similar task repeatedly without the need to create a separate task for each execution. This helps cut down on development time, reducing future maintenance with fewer changes in fewer places.
In the case of this template, there are three things I want to achieve:
- Run a Transformation Task
- Choosing whether the target table needs to be truncated
- Log the outcome to Amazon CloudWatch
Using these requirements, the functionality is the same other than minor differences such as the name of the job to be run, and if the target table requires truncating. So, the first step is to determine what information needs to pass in.
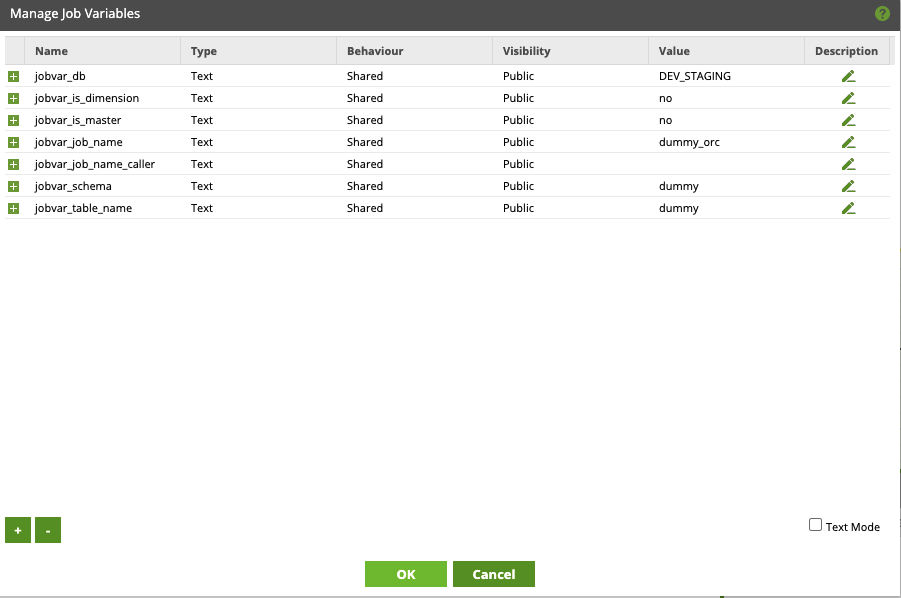
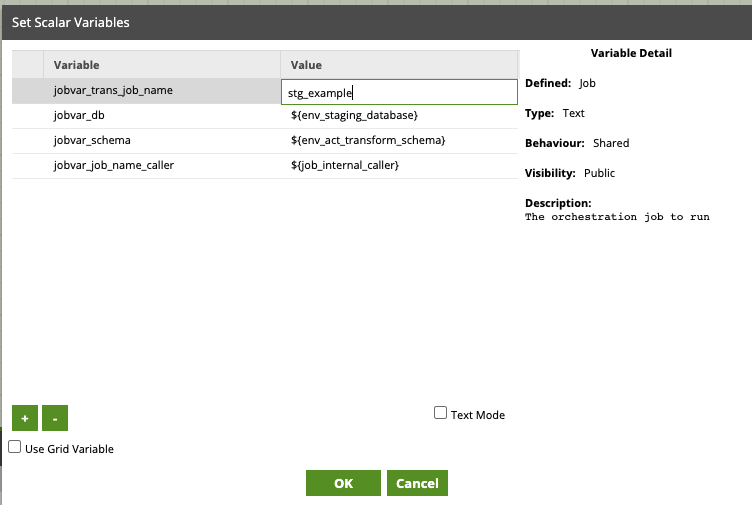
You will see in the above image that as well as passing in the task name we also pass in the database, schema and table names allowing us to control which table is truncated. You will notice that there is no reference to truncate in the job variable settings, this is because we control that at an environment level and as such is managed as an environment variable. The reason for this is that this setting can affect several different components outside of the scope of this template and as such is managed as an environmental variable.
You will also notice that many of the job variables have a default value set; this enables Matillion to compile the template.
Creating the Template
The next step is to create a generic template as below:
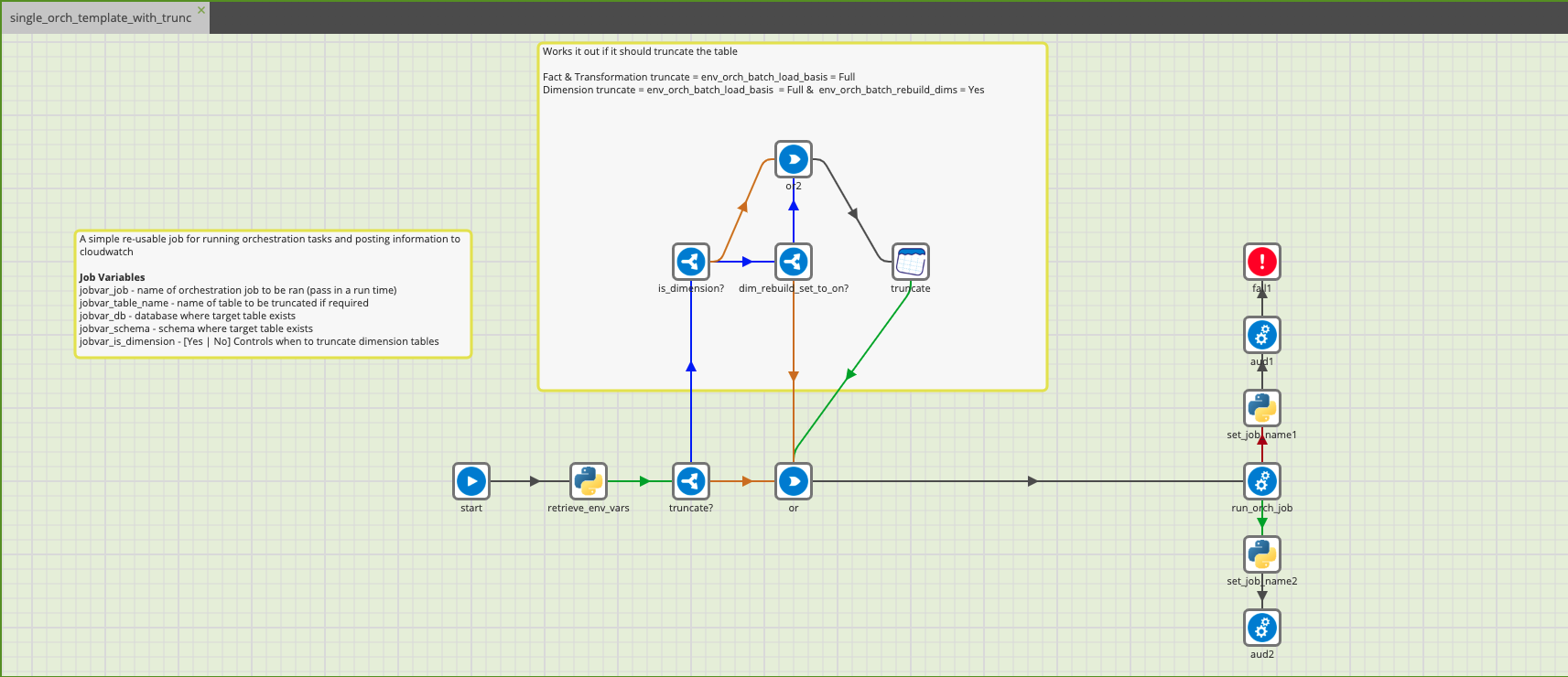
The idea is, we have no hard-coded values set (unless you know that the value will always be the same). For example, knowing a given template will always be in use in the same database or schema. However, if anything is hard-coded it defeats the object of creating the template in the first place.
Other things you will notice in the example are the use of python components. These are a powerful addition to any template. In this instance, one of the functions we are performing is to query a snowflake database table. This determines if we require a full load and sets the local variables accordingly.
It is also good practice to give definitions of each variable so that when people other than the author come to use the template it is clear what they need to pass in.
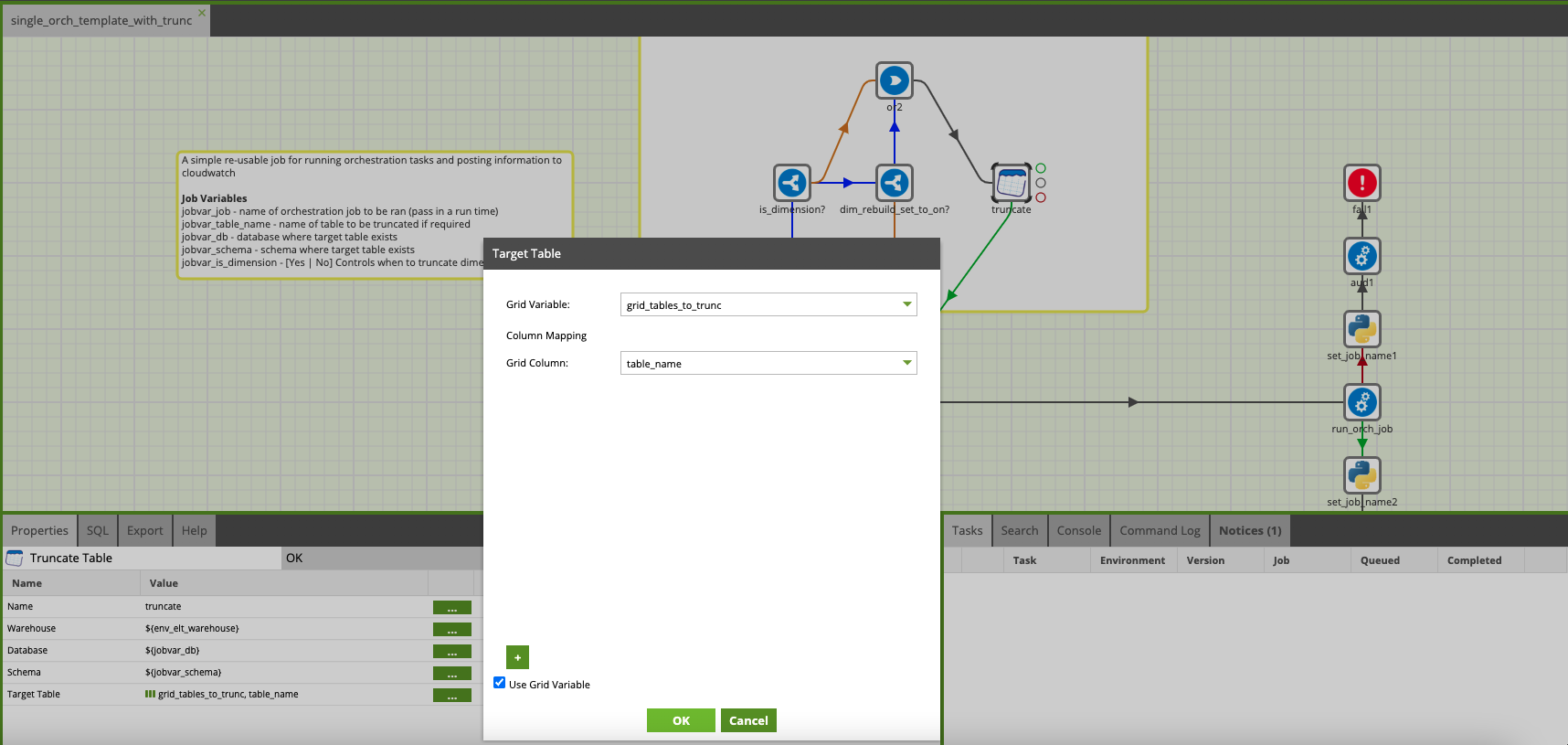
Using job variables within a template is quite simple you just need to refer to it by name in the properties window as below (note that you can use both scalar and grid variables).
Using your new Matillion Orchestration template
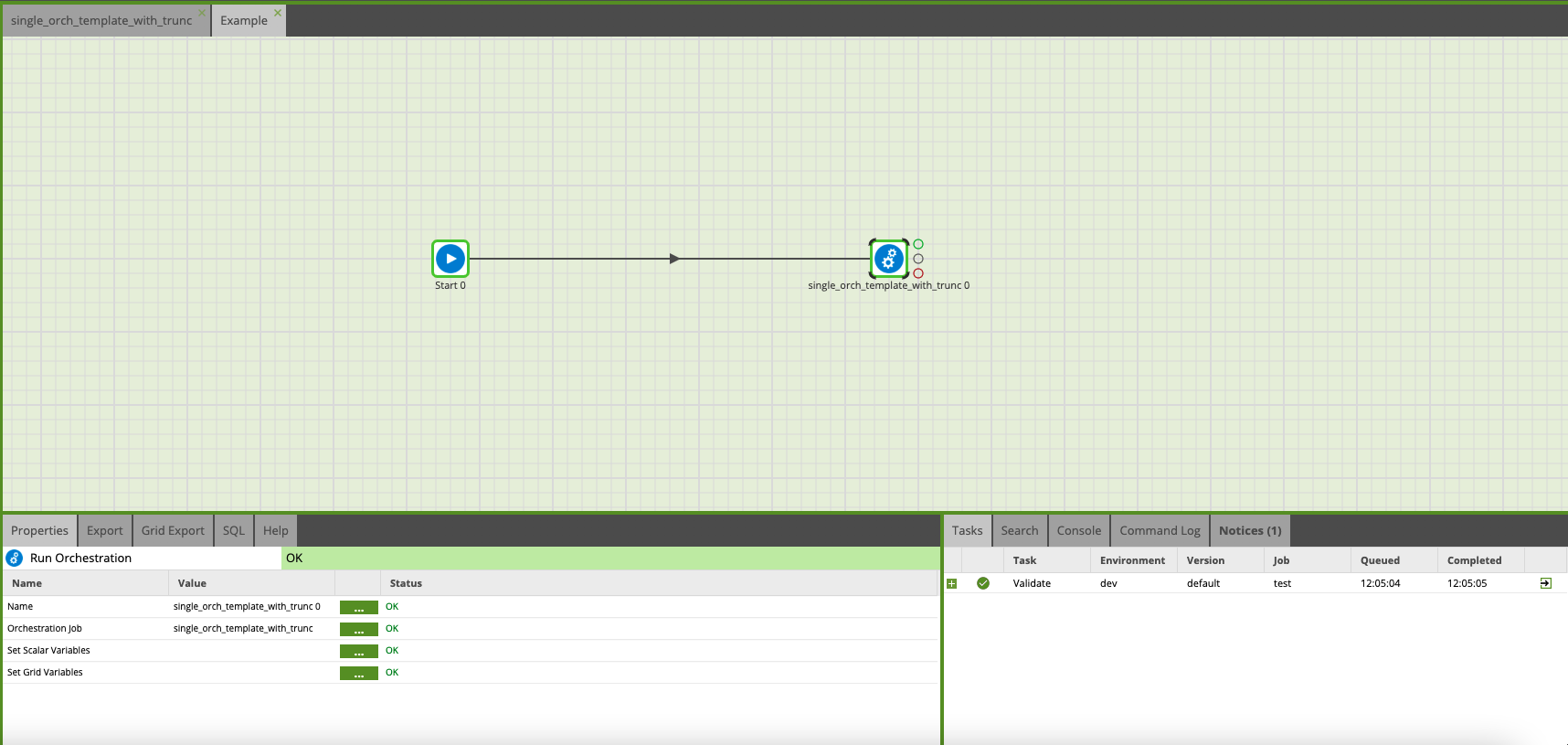
Making use of your new template is quite simple, all you need to do is:
- Drop a Run Orchestration task on the canvass
- Select your template from the dropdown
- Fill out your variables
- Run the Job!
Conclusion
Once you have set up a template, it’s easy to repeat use for any new transformation task you create. Here at synvert TCM (formerly Crimson Macaw), we use templates to orchestrate all of our Matillion projects. Meaning, once a new transformation task is active, we can add to the pipeline using a single component in seconds!
Want to know more? Get in touch with us here.