
By Dave Poole – Principal Data Engineer
Here at synvert TCM (formerly Crimson Macaw), our ability to make changes to our software at short notice, reliably and at pace define us as a high-performing team. Not only is this ability important to be competitive but also to defend against and block hostile activity. In this blog, we look at the human response to software changes.
The saying “if it ain’t broke don’t fix it” still applies, but we recognise that “broken” can change overnight and outside our control. A recent example would be the discovery of a critical vulnerability in Apache Log4J, a widely used logging package.
Whether it is patching/bug fixing or adding business capability we need to be sure that the behaviour of our apps and systems only changes in the way in which we intend. To gain the confidence that this so requires a robust test regime. A mechanical way to enact such a regime is essential if the time required to gain this confidence is not to be prohibitive.
The choice of the right test tools alone does not solve the problem. We must build up our knowledge as to their use otherwise we fall prey to the accusation of “all the gear and no idea”. For the cyclists amongst you “3 grand bike, 30 pence legs”.
Perception of risk
To earn trust and gain confidence it is important to make sure that our tests express themselves at the correct level of detail for their intended audience.
A customer may perceive fine-grained detail tests as follows.
- Detail is perceived as complexity
- Complexity is perceived as a risk
- Risk threatens confidence
This would be the opposite of the confidence we would hope tests would provide. A developer is likely to view such detail differently.
- Detail is perceived as thoroughness
- Thoroughness inspires confidence
A glimpse at test frameworks
Fortunately for us, different test frameworks cater for these different audiences. We can choose our test frameworks (plural) to satisfy our different needs. As we use Python two of the various test frameworks we use are as follows
- Behave for tests that specify and express results in business-friendly language
- Pytest for the unit tests for components that make up the higher-level business requirements
Behave allows a business analyst to specify tests in a language known as Gherkin. This uses a plain English phraseology that almost anyone can read.
Using the analogy of driving a car the “Given, When, Then” phraseology of Gherkin might describe a test as follow.
Given that the engine is running
And the car has an automatic gearbox
When I put the gear in the DRIVE position
And I release the handbrake
And I press the accelerator
Then the car moves forward
As a driver I don’t care what goes on under the car bonnet, the phraseology above is sufficient. As an engineer, I need a level of detail that would only upset a customer. The detail confirms the safety of lumps of metal hurtling up and down 130 times a second glowing from the heat of explosions from a highly flammable liquid.
The fine-grained details (unit tests) can be fulfilled by Pytest. However, the existence of such tests alone is not enough to reassure data engineers. Tests are themselves code and it is harder to read code than to write it. This truism was well described by Joel Splozky nearly a quarter of a century ago.
We take care to make sure that unit tests are written so their intent is clear to an engineer looking at the code.
Illustrating test readability
The rest of this article shows a simple test and how it becomes less readable over time and how we address this.
Let us suppose we have a function to take a line of text and determine how many delimiters exist.
We might have a test as follows.
def test_delimiter_char_count(): assert CSVLine.delimiter_character_count( "Paradise, By, The, Dashboard, Light" ) == 4
The code is quite easy to read and when the test runs in the developer’s IDE (Integrated Development Environment) simple output is produced.
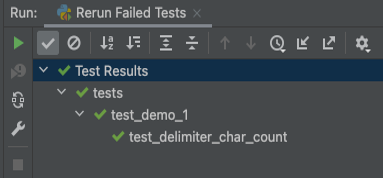
The test takes a fixed string “Paradise, By, The, Dashboard Light”, recognises the commas as delimiter characters and confirms that there are four.
This test is rather rigid and does not answer the question of what happens if other possible delimiters are present or whether the function does count the delimiters. We want to run the test for several different scenarios.
Our code would change as follows.
Import pytest
@pytest.mark.parametrize("input_string, expected_delimiter_count",
[("Paradise, By, The, Dashboard, Light", 4),
("Two, out, of, three, ain't, bad", 5),
("", 0),
("Bat|Out|Of|Hell", 3)
("For|Crying,Out\tLoud", 3),
]
)
def test_delimiter_char_count(input_string, expected_delimiter_count):
assert CSVLine.delimiter_character_count(
input_string) == expected_delimiter_count
This produces the following output
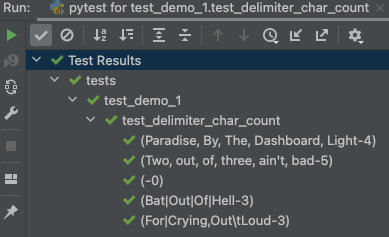
The test output does show the following.
- Commas, TABs and pipe symbols are treated as delimiters
- An empty or undelimited string does not break the code
- The delimiter characters are correctly counted
However, even in this simple example, we can see that the combination of test data and test code reduces the readability of the test for the data engineer.
We can split the test data from the test code as in the following example
import pytest
# Test data
# =========
DELIMITER_COUNT_DATA = [
pytest.param("Paradise, By, The, Dashboard, Light", 4),
pytest.param("Two, out, of, three, ain't, bad", 5),
pytest.param("", 0),
pytest.param("Bat|Out|Of|Hell", 3),
pytest.param("For|Crying,Out\tLoud", 3)
]
# Test Code
# =========
@pytest.mark.parametrize(
"input_string, expected_delimiter_count", DELIMITER_COUNT_DATA
)
def test_delimiter_char_count(input_string, expected_delimiter_count):
assert CSVLine.delimiter_character_count(
input_string) == expected_delimiter_count
As the number of tests and test data builds up this separation allows us to move the test data into a separate Python file so that the test code remains relatively easy to read.
So far, we have seen that the output from our tests is descriptive of the test being run. This is true when the arguments are primitive data types. However, when the arguments are objects the result is rather different.
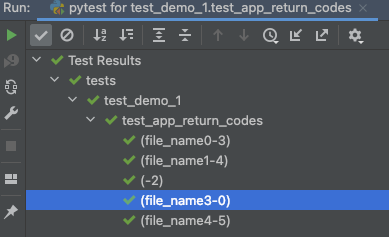
We know that we are testing the return codes received from an application in different scenarios, but we have no way of knowing what those scenarios are.
The test parameters that produced the output above may look like the following code.
import os
import pytest
from pathlib import Path
# Ensure that tests run both in the IDE and command line by starting from
# a path location relative to this file.
TEST_HOME = Path(os.path.dirname(os.path.realpath(__file__)))
TEST_DATA = TEST_HOME / "data/"
RETURN_CODE_TEST_CASES = [
pytest.param(TEST_DATA, 3),
pytest.param(TEST_DATA / "does_not_exist.csv", 4),
pytest.param("", 2),
pytest.param(TEST_DATA / "small.csv", 0),
pytest.param(TEST_DATA / "not_a_text_file.png", 5),
]
Fortunately, we can put some descriptive text in an “id” property in our pytest.param as follows.
import os
import pytest
from pathlib import Path
# Ensure that tests run both in the IDE and command line by starting from
# a path location relative to this file.
TEST_HOME = Path(os.path.dirname(os.path.realpath(__file__)))
TEST_DATA = TEST_HOME / "data/"
RETURN_CODE_TEST_CASES = [
pytest.param(TEST_DATA, 3, id="Just a folder"),
pytest.param(TEST_DATA / "does_not_exist.csv", 4, id="None existent file"),
pytest.param("", 2, id="No file supplied"),
pytest.param(TEST_DATA / "small.csv", 0, id="Valid file"),
pytest.param(TEST_DATA / "not_a_text_file.png", 5, id="Not a delimited text file"),
]
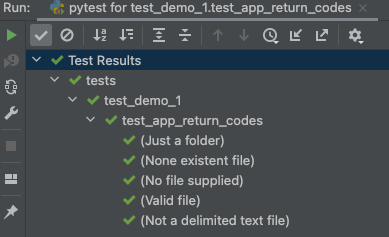
The contents of our test case “id” property will appear in the test output as shown below.
Concluding thoughts on the human response to software changes
Although this article is brief, we hope it illustrates how mechanical tests can be used to gain trust and confidence. By nurturing confidence, we reduce fear being a barrier to enacting change of software at pace.
At syvert TCM we use tools to measure how much of our applications are tested. Again, this inspires trust and confidence from both our engineers and business decision-makers.
Want to know more about how we can help you with a human response to software changes? Get in touch with us here.