
By Andres Altena – Data Science Consultant
Intro: AWS SageMaker Training Modes
In this blog series, we will cover the different ways to set up a training job in SageMaker. We recommend being familiar with how SageMaker uses Docker containers – check out our blog on this here. In this part of the AWS SageMaker Training Modes series, we will be looking at the Built-in Algorithms SageMaker has. In Part 2 we will look at Script Mode and in Part 3 we will look at Bring your own Docker containers (BYODC).
We’re focussing on training, so let’s look at the process highlighted in the diagram below. When training a model, SageMaker spins up an EC2 instance, takes a Docker image from ECR and runs the Docker container within the EC2 instance.
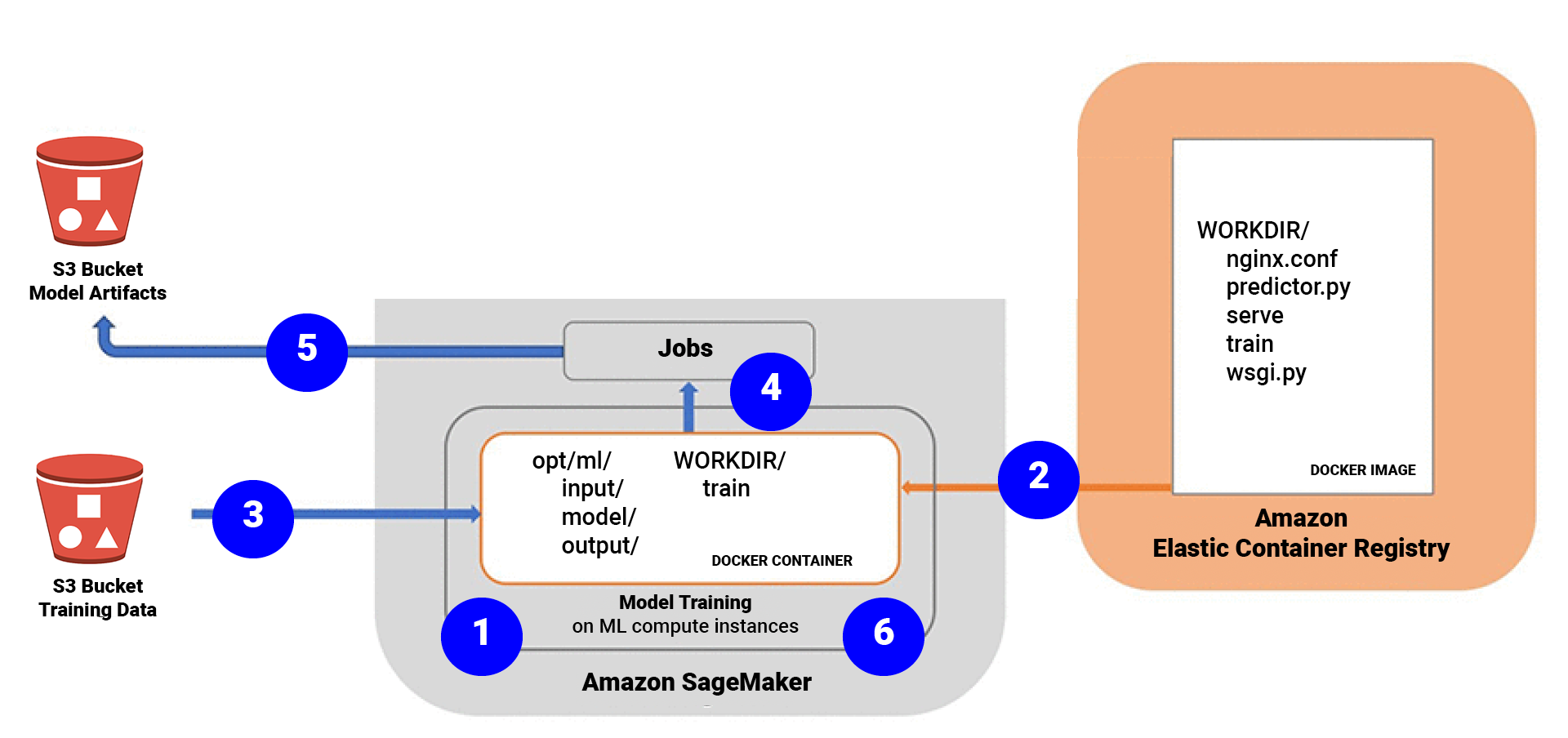
There are three main ways to provide the Docker image:
- Built-in algorithms
- Script Mode
- Bring your own Docker container

There is a trade-off between the level of effort and flexibility. In the next sections, we’ll have a look at each of these, discussing when to use each of the options.
Built-in Algorithms
The lowest level of effort and freedom.
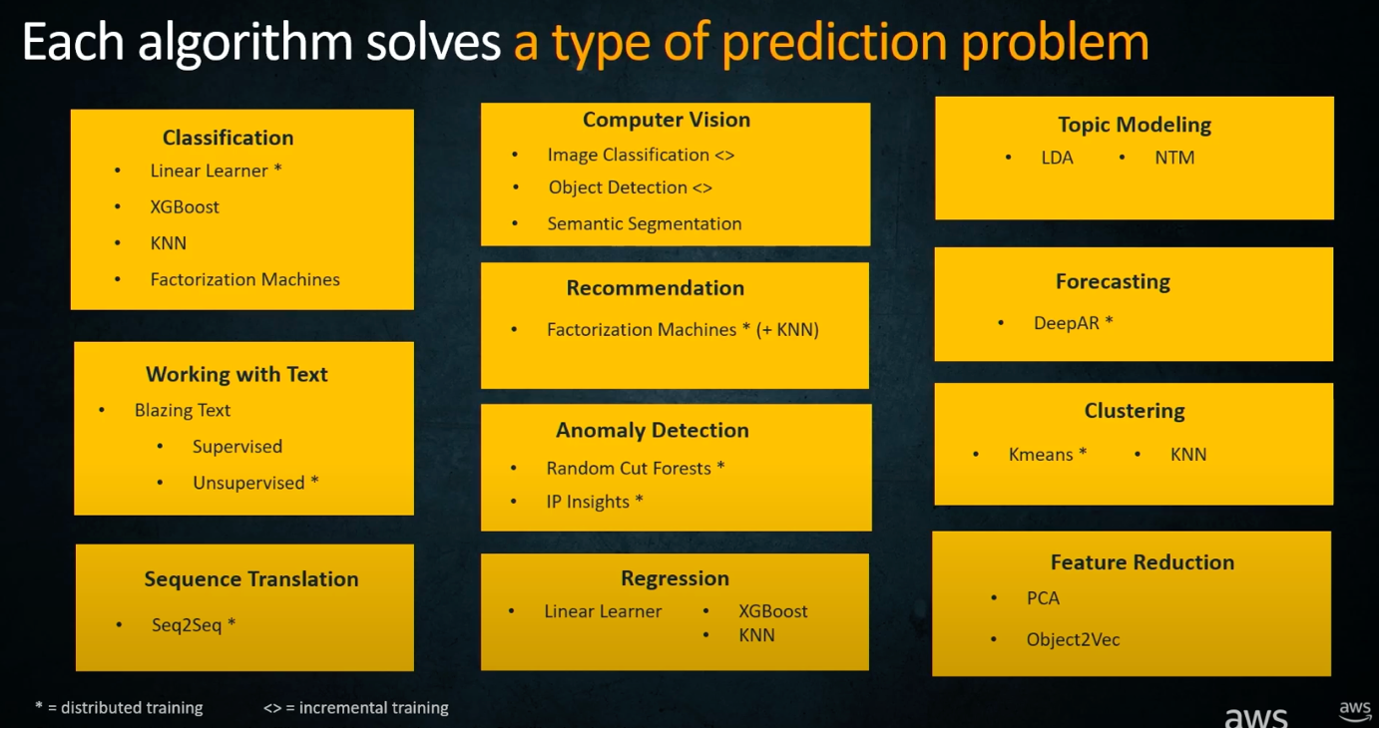
SageMaker provides a large variety of built-in algorithms which can be used to tackle a range of different problems, such as regression, classification, NLP (e.g., using HuggingFace), and Computer Vision. These models have been containerised and stored within ECR by Amazon, all you must do is tell SageMaker the location of the image, and then you’re ready to call the fit method.
The image below shows a summary of most of the models provided, together with their use cases:
Code example
In this quick demo we’ll explore the two main ways to use built-in algorithms – first by importing the model from SageMaker; and then by defining the location within ECR. You will see the overall steps are very similar, and the result is identical but let’s have a look at both options.
Option 1: import model from SageMaker
When importing the algorithm from SageMaker, you have essentially obtained the image you’re going to be using. You then must create an estimator of this type, and then you’re ready to train.
There are a few ways to pass the hyperparameters, here we have directly passed them as arguments when creating the estimator:
import sagemaker
from sagemaker import RandomCutForest
# Define session and role (this will be different if running locally)
session = sagemaker.Session()
execution_role = sagemaker.get_execution_role()
# Create estimator of type RandomCutForest
model = RandomCutForest(
role=execution_role,
instance_count=1,
instance_type="ml.m4.xlarge",
data_location=data_loc,
output_path=f"s3://{bucket}/{prefix}/output",
num_samples_per_tree=512,
num_trees=50,
)
# Train the model using data type TrainingInput
model.fit({"train": s3_train_data})
Option 2: define a location within ECR
For this option you’ll have to explicitly get the model image from ECR and pass it as an argument when creating an estimator, the rest is very similar to option 1.
Here we have set hyperparameters by calling the `set_hyperparameters` method on the estimator.
import sagemaker
import boto3
# Define session and role
session = sagemaker.Session()
role = sagemaker.get_execution_role()
# Obtain model image from ECR
container = get_image_uri(boto3.Session().region_name, "linear-learner", "latest")
# Create estimator
model = sagemaker.estimator.Estimator(
container,
role,
instance_count=1,
instance_type="ml.c4.xlarge",
output_path=output_location,
sagemaker_session=sess,
)
#Set hyperparameters - can also be done within the estimator definition
model.set_hyperparameters(feature_dim=14, predictor_type="binary_classifier", mini_batch_size=200)
#Train model with data type TrainingInput
model.fit({"train": s3_train_data})
When should you use these?
This is by far the easiest and quickest way to train a model. If one of the models offered satisfies your use case and requirements, then I would recommend using this. Since there is a large variety of models offered, this will be all you need to learn for most projects.
Even if your use case requires a custom model, you can probably find a built-in algorithm you can use as a baseline to compare model performance.
Why shouldn’t you use it?
If you know (perhaps from previous experience) that the model you want to use is not provided by SageMaker. In this case, you’ll have to do some more coding to define the model you want to use.
Conclusion
That’s it for Part 1, please keep an eye out for Part 2 soon!
Interested in talking more about what Machine Learning can do for your business? Please get in touch here.